Prompt injection is #1 on the OWASP Top 10 for LLMs and has consistently been a top security concern for AI Agents. Simon Willison illustrates this risk in the following diagram he posted on his blog.
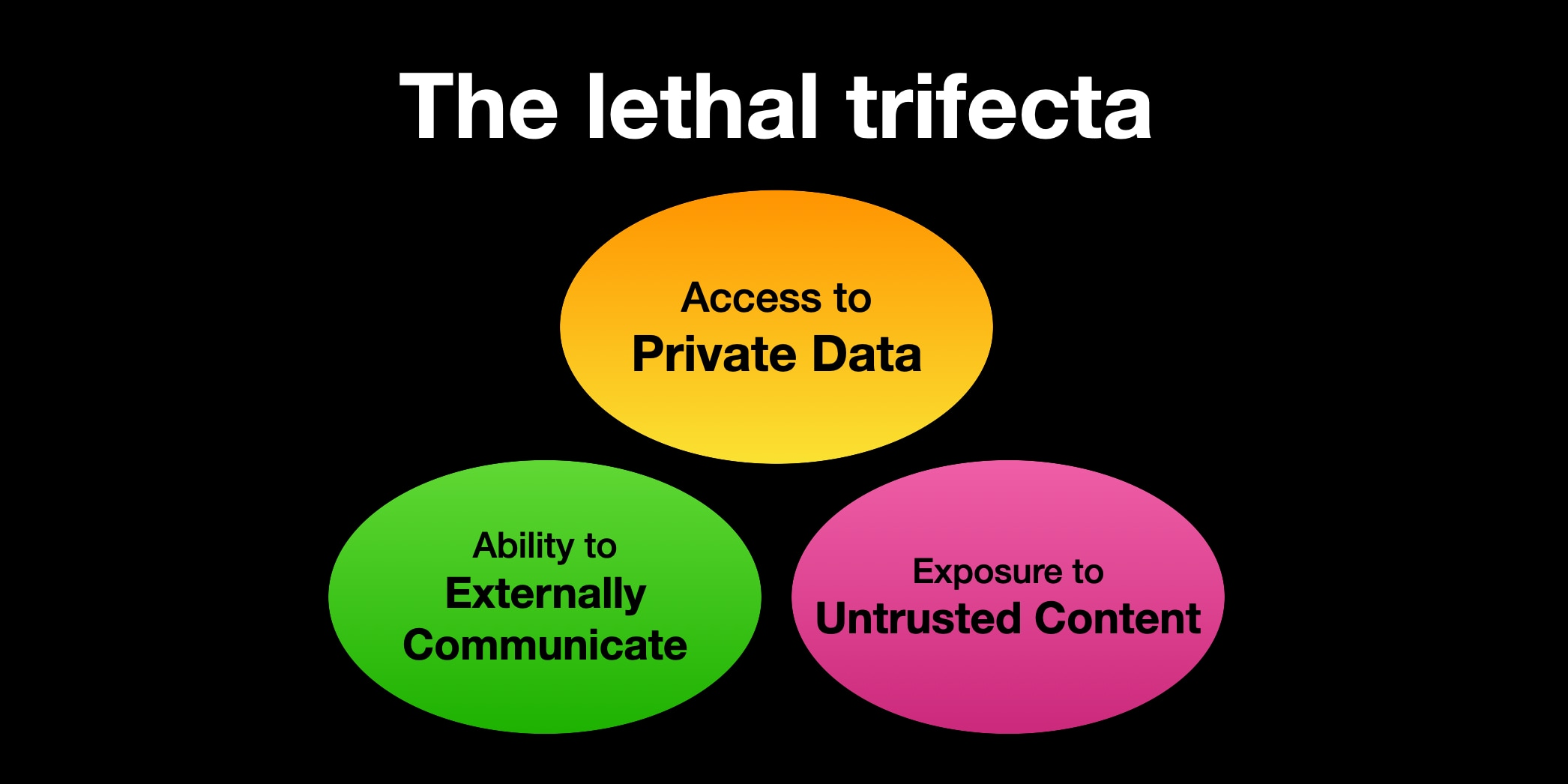
When agents fall victim to prompt injection attackers can take advantage of whatever tools or data the agent has access to. A recent example published by Invariant Labs explains how an indirect prompt injection placed in a GitHub Issue that the agent reads in causes the agent to follow the directions laid out in the issue and retrieve sensitive information about the author.
Some of the top ways to defend against prompt injection are LLM guardrails or new architectural design patterns laid out in the paper, Design Patterns for Securing LLM Agents against Prompt Injections, which came out on June 11th.
Simon Willison published a great summary of the paper which I encourage you to check out. One of the most clever design patterns in my opinion is the Dual LLM Pattern where one agent calls tools or does the web scraping and interacts with untrusted data while another drafts a response to be augmented with data the other LLM brings back. This is helpful because this prevents the untrusted data from influencing what the agent will do or how it will respond.
Defending against threats like prompt injection is key for building Trustworthy AI. If you’re curious to learn more about what it takes to build Trustworthy AI you can book time with me or checkout my 20 minute talk on AI Engineer’s YouTube page. In short Trust is built with MLSecOps, red teaming, evals, AI Runtime Security also known as LLM Guardrails, and compliance.